在本文中,本土獨角獸依圖科技提出了一個小而美的方案——ConvBERT,通過全新的注意力模塊,僅用 1/10 的訓練時間和 1/6 的參數就獲得了跟 BERT 模型一樣的精度。相比費錢的 GPT-3,這項成果可讓更多學者用更少時間去探索語言模型的訓練,也降低了模型在預測時的計算成本。本文已被 NeurIPS 2020 接收。
今年 5 月,Open AI 發布了非常擅長「炮制出類似人類的文本」的 GPT-3,擁有破天荒的 1750 億參數,一時被業界視為最強大的人工智能語言模型。
可是,訓練成本極高,難以普及,也成了 GPT-3 成功背后的不足。相對于通用的計算機視覺模型,語言模型復雜得多、訓練成本也更高,像 GPT-3 這種規模的模型只能是工業界才玩得起。
深度學習「教父」LeCun 也說:「試圖通過擴大語言模型的規模來建造智能應用,就像建造一架飛往月球的飛機。你可能會打破高度記錄,但是登上月球其實需要一種完全不同的方法。」
本土獨角獸依圖科技最近在人工智能界頂會 NeurIPS 上提出了一個小而美的方案——ConvBERT,通過全新的注意力模塊,僅用 1/10 的訓練時間和 1/6 的參數就獲得了跟 BERT 模型一樣的精度。相比費錢的 GPT-3,這項成果可讓更多學者用更少時間去探索語言模型的訓練,也降低了模型在預測時的計算成本。
今年的 NeurIPS 創紀錄接收并審閱了來自全球的 9454 篇論文,但最終僅 1900 篇論文被收錄,錄用率為 20.09%,創歷年來接受率最低紀錄。問題不夠令人興奮者,不可收也。被收錄的論文更顯珍貴。
依圖的這篇論文提出了基于區間的新型動態卷積,在自然語言理解中證明有效,在計算機視覺領域也可使用。這是依圖繼 ECCV 2020 之后,連續開放的第二項主干網絡基礎性改進工作。

預訓練語言理解新模型 ConvBERT,超越谷歌 BERT
最近 BERT 這一類基于預訓練的語言理解模型十分流行,也有很多工作從改進預訓練任務或者利用知識蒸餾的方法優化模型的訓練,但是少有改進模型結構的工作。依圖研發團隊從模型結構本身的冗余出發,提出了一種基于跨度的動態卷積操作,并基于此提出了 ConvBERT 模型。
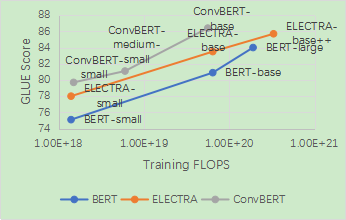
這一模型在節省了訓練時間和參數的情況下,在衡量模型語言理解能力的 GLUE benchmark 上相較于之前的 State-of-the-art 方法,如 BERT 和 ELECTRA,都取得了顯著的性能提升。其中 ConvBERT-base 模型利用比 ELECTRA-base 1/4 的訓練時間達到了 0.7 個點的平均 GLUE score 的提升。
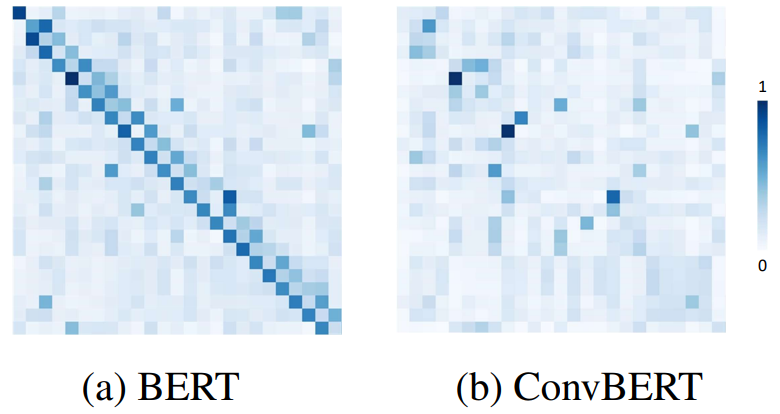
之前 BERT 這類模型主要通過引入自注意力機制來達到高性能,但是依圖團隊觀察到 BERT 模型中的 attention map 有著如下圖的分布(注:attention map 可以理解成詞與詞之間的關系),這表明了大多注意力主要集中在對角線,即主要學習到的是局部的注意力。這就意味著其中存在著冗余,也就是說很多 attention map 中遠距離關系值是沒有必要計算的。

于是依圖團隊考慮用局部操作,如卷積來代替一部分自注意力機制,從而在減少冗余的同時達到減少計算量和參數量的效果。
另一方面,考慮到傳統的卷積采用固定的卷積核,不利于處理語言這種關系復雜的數據,所以依圖提出了一種新的基于跨度的卷積,如下圖所示。原始的自注意力機制是通過計算每一對詞與詞之間的關系得到一個全局的 attention map。
此前有文章提出過動態卷積,但其卷積的卷積核并不固定,由當前位置的詞語所代表的特征通過一個小網絡生成卷積核。這樣的問題就是在不同語境下,同樣的詞只能產生同樣的卷積核。但是同樣的詞在不同語境中可以有截然不同的意思,所以這會大大限制網絡的表達能力。
基于這一觀察,依圖提出了基于跨度的動態卷積,通過接收當前詞和前后的一些詞作為輸入,來產生卷積核進行動態卷積,這在減少了自注意力機制冗余的同時,也很好地考慮到了語境和對應卷積核的多樣性。
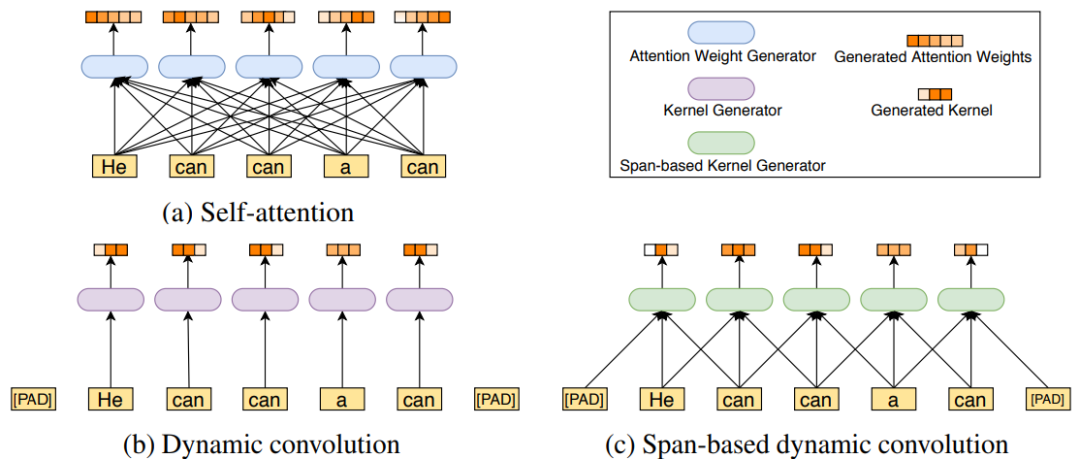
基于跨度的動態卷積,同時減少原模型冗余和參數量
具體而言,引入了一個輕量卷積的運算操作,
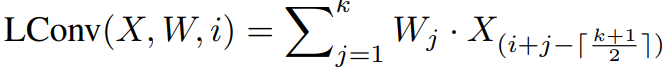
其中X∈R^n×d 為輸入的特征,而W∈R^k 則是卷積核,k 為卷積核的大小。輕量卷積的作用是將輸入的每個詞對應的特征附近的 k 個特征加權平均生成輸出。在此基礎上,之前提到的動態卷積可以寫作
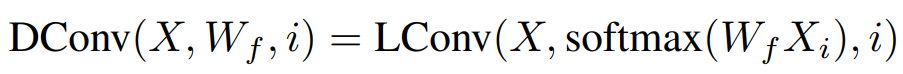
此處卷積核是由對應的詞的特征經過線性變換和 softmax 之后產生的。為了提升卷積核對于同一詞在不同語境下的多樣性,依圖提出了如下的動態卷積
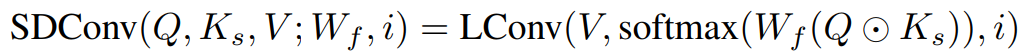
此處,輸入 X 先經過線性變換生成Q和V,同時經過卷積生成基于跨度的K_s,由Q⊙K_s經過線性變換以及 softmax 來產生卷積核與V進一步做輕量卷積,從而得到最終的輸出。
在基于跨度的卷積的基礎上,依圖將其與原始的自注意力機制做了一個結合,得到了如圖所示的混合注意力模塊。
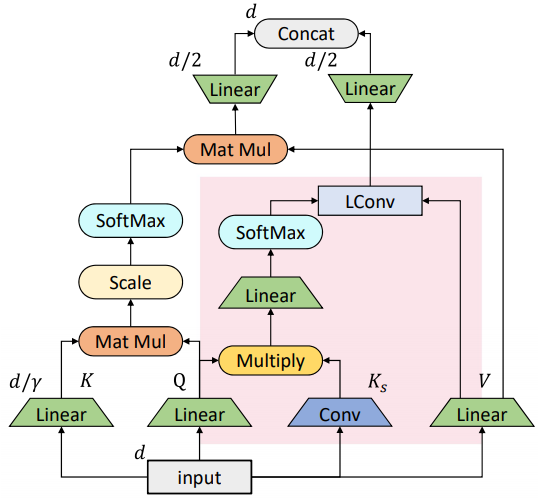
可以看到,被標紅的部分是基于跨度的卷積模塊,而另一部分則是原始的自注意力模塊。其中原始的自注意力機制主要負責刻畫全局的詞與詞之間的關系,而局部的聯系則由替換進來的基于跨度的卷積模塊刻畫。
從下圖 BERT 和 ConvBERT 中的自注意力模塊的 attention map 可視化圖對比也可以看出,不同于原始的集中在對角線上的 attention map,ConvBERT 的 attention map 不再過多關注局部的關系,而這也正是卷積模塊減少冗余的作用體現。
對比 state-of-the-art 模型,ConvBERT 所需算力更少、精度更高
為分析不同卷積的效果,依圖使用不同的卷積得到了如下表所示的結果
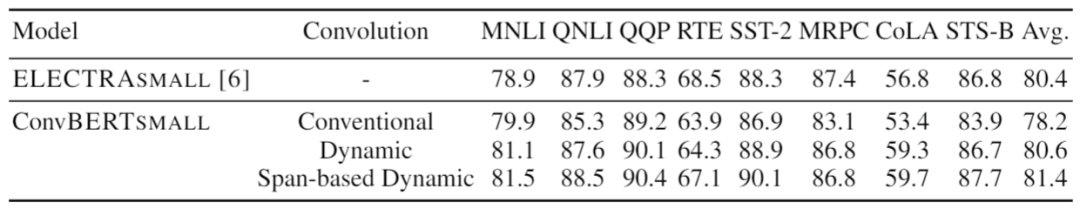
可以看出在模型大小一致的情況下,傳統卷積的效果明顯弱于動態卷積。并且,本文提出的基于跨度的動態卷積也比普通的動態卷積擁有更好的性能。
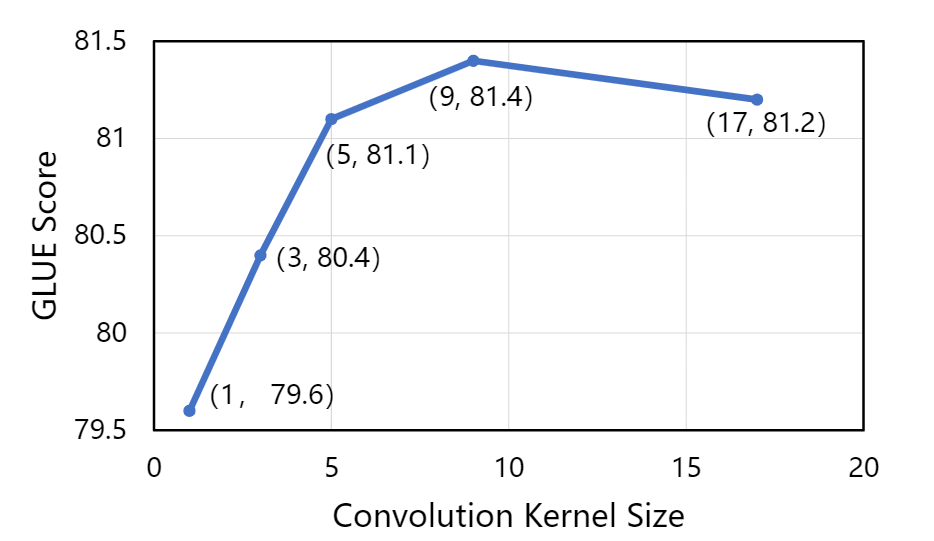
同時,依圖也對不同的卷積核大小做了分析。實驗發現,在卷積核較小的情況下,增大卷積核大小可以有效地提高模型性能。但是當卷積核足夠大之后提升效果就不明顯了,甚至可能會導致訓練困難從而降低模型的性能。
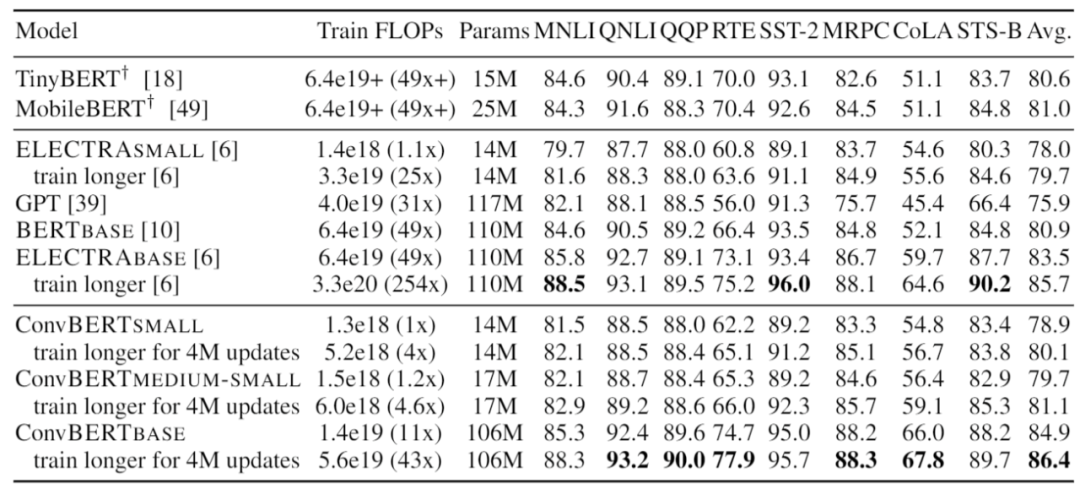
最后,依圖將提出的 ConvBERT 模型在不同的大小設定下與 state-of-the-art 模型進行了對比。值得注意的是,對小模型而言,ConvBERT-medium-small 達到了 81.1 的 GLUE score 平均值,比其余的小模型以及基于知識蒸餾的壓縮模型性能都要更好,甚至超過了大了很多的 BERT-base 模型。而在大模型的設定下,ConvBERT-base 也達到了 86.4 的 GLUE score 平均值,相比于計算量是其 4 倍的 ELECTRA-base 還要高出 0.7 個點。
您可以復制這個鏈接分享給其他人:http://www.jisvip.com/node/879




